Taking down (and restoring) the Raygun ingestion API
Posted Oct 15, 2023 | 7 min. (1390 words)In a world where Software as a Service (SaaS) products are integral to daily life, maintaining uninterrupted service for end-users is paramount. However, stuff happens. When it does, our most valuable response (other than restoring service ASAP) is to review the series of events that led up to the incident and learn from them.
On August 25th, 2023, at 7:02 AM NZT, Raygun experienced a significant incident that impacted our API ingestion cluster, leading to an outage lasting approximately 1 hour and 15 minutes. While this wasn’t fun for anyone involved, this incident did prove to be a valuable learning experience, shedding light on the importance of infrastructure management and resilience.
What went wrong?
The incident traces back to a routine infrastructure cleanup that inadvertently disrupted critical components. Two days prior to the outage, on August 23rd, our team was cleaning up old AWS Classic load balancers (LBs) as part of our infrastructure maintenance. These load balancers were associated with the Auto Scaling Group (ASG) of the API nodes which handle all our incoming data ingestion requests. However, the removal of these load balancers went unnoticed and unmonitored, ultimately causing the failure of the ASG and the ingestion API.
Unpacking the jargon
Before we delve deeper, let’s unravel some of the terms we’re using for those unfamiliar with the nuances of cloud system architecture.
- AWS Elastic Load Balancer (ELB): Load balancers distribute incoming network traffic across multiple servers to ensure no single server becomes overwhelmed, enhancing system performance and reliability. AWS Classic Load Balancers are a type of load balancer provided by Amazon Web Services. Other LB types include Classic, Application, Network, Gateway etc., each with its own distinctive features and purpose.
- AWS Auto Scaling Group (ASG): An Auto Scaling Group allows you to automatically adjust the number of compute resources (instances) in a group to match the demand. ASG can be configured on aspects such as launch templates, instance types, load balancing, health checks, and other configurations that allow us to configure the instances while they are launched. Then there are scaling policies to allow us to manage the scaling properties of ASG, which can be scheduled, dynamic, or predictive in nature, based on factors like resource load on instances or the applications etc.
- Target Groups (TG): Target groups direct incoming requests to specific registered targets—such as EC2 instances—based on defined protocols and port numbers. It’s possible to associate a target with multiple target groups and set up health checks on a per-target group level. These health checks apply to all targets registered within a target group specified in a listener rule for your load balancer.
- OOM (Out of Memory): This term refers to a situation where a computer program tries to use more memory space than is available.
Incident timeline and root cause analysis
The root cause of the incident traces back to actions taken on August 23rd, 2023.
Our engineering team was (and is) engaged in a major project to “tidy up” our code base, pausing core product development for two months to complete our upgrade to .NET 6 (in prep for an upcoming move to .NET 8 at the end of the year), improve DX around our CI/CD (honing a workflow that combines JetBrains, TeamCity, and Octopus Deploy), and simplifying our front end code.
While engaged in this clean-up work, the team deleted several AWS load balancers (LBs). We were operating on the belief that none of these LBs were in active use, though some were associated with our API cluster. However, this deletion inadvertently disrupted the auto-scaling group (ASG) setup, preventing it from adding new instances to maintain the desired capacity.
Unknown to us, over the course of the next two days, the ASG struggled to add instances, causing a strain on the existing infrastructure. The ASG is configured to scale up to 40 instances with a minimum requirement of 4 instances. The system continued to operate with just three nodes (ASG deemed one of the instances unhealthy and terminated it), managing all traffic without apparent signs of failure until the morning of August 25th.
At 7:02 AM on August 25th, an on-call engineer received the first alerts indicating that api.raygun.com was down. Errors on the load balancer skyrocketed, reaching approximately 100,000 HTTP 503 errors per minute (quite the increase from our usual 10-odd/minute). The team detected an OutOfMemory (OOM) exception on one of the nodes in our Raygun crash reports (yes, we use Raygun to monitor our own apps!), signaling the start of the incident. Subsequent exceptions and alerts pointed to a systemic failure of the ingestion pipeline across the board.
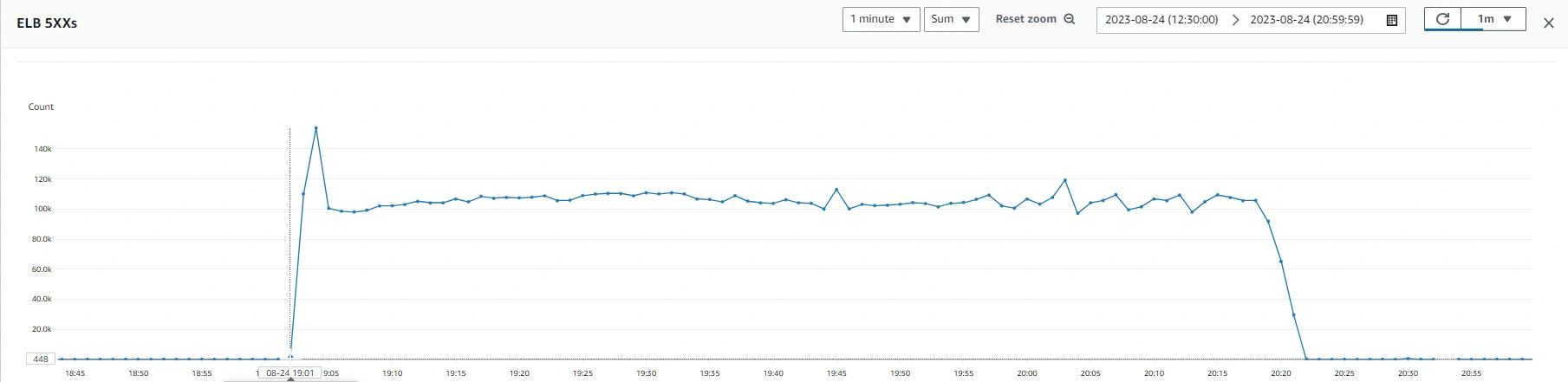
Our immediate efforts to troubleshoot the issue included trying to remove and add nodes manually to the API ASG and attempting to roll back recent deployments. To immediately prevent any further customer data loss, we paused the investigation to manually create a highly-resourced monolith instance and rerouted all traffic to it. This measure allowed Raygun to resume processing data at 8:20am, with some performance issues. This interim fix bought us more time to find a more robust solution.
Restoring operations
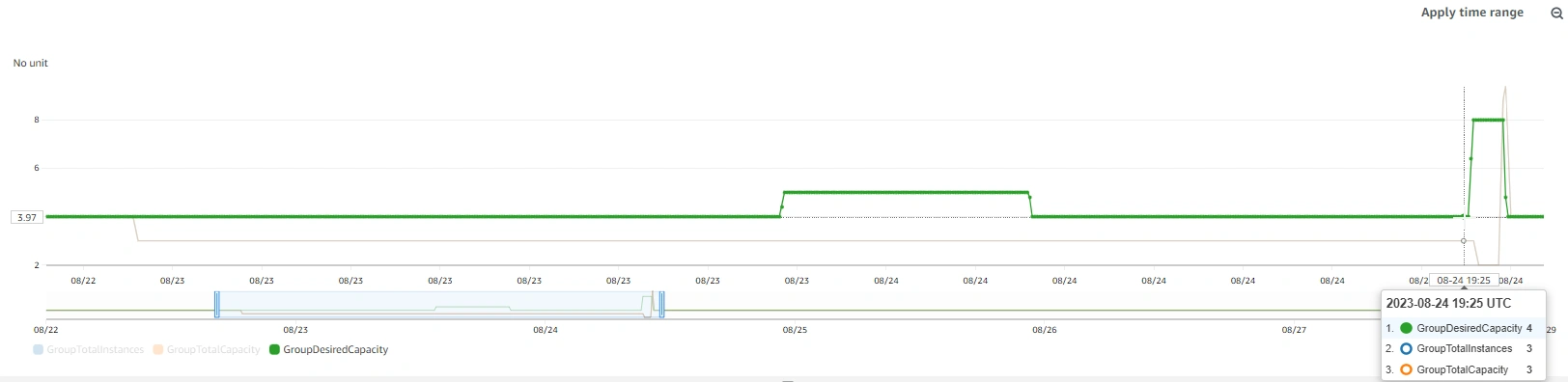
The monolith API node got the ingestion pipeline up and running, which allowed us to identify the issue with the ASG groups. At 8:35am the ASGs were reconfigured and traffic was switched back to the API cluster. After resolving the issue and re-establishing the desired configuration, Raygun resumed ingesting data and processing requests, and declared the end of incident at 8:50am.
Lessons learned
AWS ASGs are highly configurable, and one of the options to configure is adding or removing nodes from a set of load balancers, regardless of type. We had used Classic load balancers (CLB) on our API nodes originally, which were replaced by the Application load balancers (ALB) when these became generally available. Due to other internal dependencies, the old load balancers were never removed from the config nor deleted. Over the years, we migrated those dependencies; however, the CLBs still remained.
Ideally, AWS would provide validation to state the dependency while removing a CLB if it was associated with an ASG, especially if it could lead to failure of the ASG’s functioning. Unfortunately, this isn’t the case, which allowed us to remove CLB without having a clue that ASG would fail to scale due to the CLB still being present in the config. We further tested this on the target groups by removing a TG that wasn’t associated with any LBs but was part of an ASG config. We were able to remove it, and the ASGs failed again due to missing TG. Lesson learned!
This incident highlighted the value of observability, and the necessity of understanding the intricate dependencies within an IT infrastructure. The unnoticed removal of Classic load balancers had a cascading effect, causing subsequent failures. While AWS has other validations for removal of interdependent services, this was a place where it was missed dearly.
We also experienced firsthand the necessity of robust monitoring and alerting systems here. The Raygun team responded by implementing additional alerts to monitor our ASGs, and TGs to ensure early detection of anomalies and to expedite issue resolution.
Taking the next proactive step, we have initiated a larger project to consolidate our current state of observability and make it much more accessible for an engineer while responding to incidents. While this will be a big piece of work, as a first step, we’ve grouped together the alerts into sensible categories to reduce the noise generated during such incidents.
Moving forward
Raygun has taken this incident as a learning opportunity, and we’re committed to fortifying our systems to prevent similar occurrences in the future.
This outage underscores the dynamic nature of technology and the constant need for vigilance and adaptability. As makers of monitoring tools ourselves, it gives us a renewed appreciation for how we can support our customers. It is a bit ironic that this incident happened while engaged in work intended to reduce our technical debt and make our product more robust going forward. At the same time, it proves the value of this work, as this revealed a dependency that we’d overlooked for years and has ultimately strengthened our systems and our incident response processes. Raygun’s dedication to learning from this incident and enhancing our infrastructure sets us up well for the future, assuring customers a more resilient and reliable service.