How to implement a Blameless Postmortem (part two)
Posted Apr 6, 2022 | 8 min. (1633 words)This is Part 2 of a two-part series on Blameless Postmortems. The previous article went into why blameless postmortems are so effective; this second part goes into detail on how to build your own postmortem process and kick it into overdrive. Read Part 1 here.
So you’ve read our first installment and recognized the value of the blameless postmortem for efficiency, culture, and output. Now you’re ready to get off the blame train and kickstart a blameless postmortem process of your own. Where to begin?
Who’s attending?
First off, who should be on the invite list? With few exceptions (e.g to protect sensitive information or somebody’s personal privacy), make it an open session, available to everyone who wants to attend. At the very least, you’re going to want to make sure that the meeting notes and action items are shared openly. It’s especially important that the key stakeholders attend; people that introduced the defect, and those that identified and fixed it.
Secondly, you’re going to want to have a facilitator present to call out bias. The facilitator keeps the discussion productive and fair. The facilitator is going to keep things on the rails with the mindset that these are complex systems and we have an imperfect understanding of dependencies, so how do we make our changes safer and provide more information next time?
What’s on the agenda?
Some basic principles that should be established first and that the facilitator should bring up again if rules are broken:
- People are never the problem; process and automation are usually the real culprits.
- We’ll provide safety and openness about errors and mistakes over punishment and blame, as learning begins with accountability, humility, and transparency. The engineers most directly involved in the incident have the highest priority to suggest and implement remediation steps.
- We will invite everyone to the postmortems as an open lab, including business stakeholders and the engineers / on-call staff involved in the incident.
- A facilitator enforces rules of behavior. In particular, counterfactual language like “could have”, “should have”, etc that promotes the illusion of one single (human) point of failure.
- Every postmortem should have at least one short- and one long-term action or remediation work item (i.e. not all incidents are repeatable or deserve a full postmortem).
- Action items usually come down to making more and higher quality information available to those on the team - especially around automation, logging, documentation, dashboarding, and error alerts. Too many action items are as bad as none at all.
Format:
- 1 min - Opening statement by facilitator to set expectations
- 5 min - impact to customers / partners.
- 15 min - Timeline. What happened exactly and when? All relevant dates and events need to be listed in order.
- 5 min - What went well?
- 15 min - What didn’t go well? (i.e. what do we need in order to avoid repeating)
- 15 min - Action items
Ahead of time, the facilitator should ask people to contribute to the timeline so we have an accurate understanding of the facts. Regardless, you won’t get too far off course if you keep the following one-sentence mantra in mind - call it a Retrospective Prime Directive:
“Regardless of what we discover, we understand and truly believe that everyone did the best job they could, given what they knew at the time, their skills and abilities, the resources available, and the situation at hand.”
– Norm Kerth, Project Retrospectives: A Handbook for Team Review
Why a timeline?
Good blameless postmortems focus on guardrails, not punishment. So any postmortem begins with what was known and the order of events. Logs, chatroom records, release notes - any and all data establish what happened and when. The goal here isn’t to come up with remediation steps but to understand context. What was known at that time, and why did the decisions and actions taken make sense to those on the scene? These facts must be agreed on before the group can continue.
Often you’ll discover a “fog of war” - people lacked information on what was really going on, or there were hidden ‘gotchas’ or dependencies that led to a cascading chain of failures. Once everyone understands what was truly missing, we can start with the next step, building better guardrails and processes.
As an example, here’s an ASP.NET request cycle presented in Raygun.
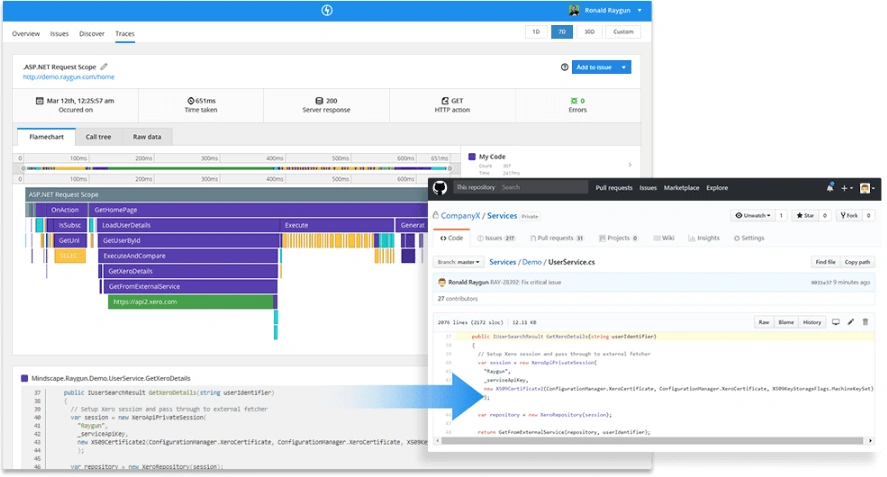
An objective data-gathering tool like this, that shows the page lifecycle live and allows first responders to drill into root causes quickly, can help immensely in reducing MTTD/MTTR. Yet very rarely in our experience are support or engineering teams given this kind of visibility. Instead, they’re asked to pore through disparate and cluttered server logs, trying to find the customer’s experience buried in a haystack of raw data.
Often a postmortem will reveal hours, sometimes days, of “flail”: where there was no single source of truth, people were acting on incomplete or dated information, and hidden performance bottlenecks suddenly escalated into full-blown outages. Good postmortems will avoid calling out specific teams or training as an action item, but will often look into missing or flawed monitoring and alerting systems as a great low-cost action item to implement following an outage.
Remediation Items
Nobody likes long meetings that go nowhere. Postmortems require a lot of time. You’re going to want to make sure this isn’t just a talking exercise but actually pays off for your company with some clear, well-defined action items.
You’ll be preparing in follow-up a list of what went well, what didn’t work well, and how luck played a hand. This list should be searchable (Etsy has made a publicly accessible tool called Morgue that acts as a database for first responders). The key, though, is to make sure we close the loop. There must be at least one well-defined action item that is entered into your tracking system as a work item. An action item should typically take no more than 30 days to complete and only very rarely in months.
Some rules of thumb from the excellent SRE workbook by Google:
- Are the action items realistic and vetted with product owners?
- Have you considered ways to improve both prevention and resolution time?
- Have you considered similar or “rhyming” incidents and their corresponding action plans?
- Have you considered how to automate ways to prevent humans from making mistakes?
- Does your postmortem have at least one Critical Priority or High Priority action item? If not, is the risk of recurrence accepted by stakeholders?
- Have you negotiated the execution of action items with the responsible group(s)?
(PagerDuty’s template is good as well. The key is timing - the template points out that any effective postmortem should be scheduled within 5 business days of an event).
If the group leaves without having at least 1-2 new work items dropped into the dev backlog, including some way of measuring if the changes are producing the desired outcomes, the meeting has not reached its objective. If your facilitator is doing their job, action items will not read as vague and unhelpful directives like “make the Operations team smarter”. Our goal is to dispel some of that fog of war. This could be gaps in runbooks or documentation, handoff issues with critsits, better notifications, and alerting. In the best postmortems we’ve observed, often it comes down to visibility. This is an open discussion on anything that can improve robustness, lessening the time to detect issues and implement a fix.
If the root cause is determined to come down to one specific person or team and not some tweak to sharing knowledge, adding better alerts or monitoring, or improving support triage, we’d suggest you haven’t dug deep enough into “the second story”.
Good companies understand that mistakes are a byproduct of work. Incidents are going to occur and outages will happen. What can be done though is to prepare - how can we have better, more helpful information? How do we have a better understanding of our systems, and what tools can we give our people on the front lines? Instead of trying to find one miracle fix that will prevent a (very narrow) something from happening next time, we focus on thinking about tools and information that might address a spectrum.
Wrapping up
Your company right now may look close-up like a shambles, stumbling every day from one new crisis or disaster to the next. Take comfort! All those unicorn high-achieving companies everybody aspires to - Netflix, Google, Microsoft, Etsy, Meta - were disasters from a stability standpoint early on.
It wasn’t that these companies didn’t stumble. What set them apart is their ability to learn from mistakes versus shooting messengers. Under each of these very different companies is a single common thread – a willingness to acknowledge and learn from failure, a blame-free culture. It’s okay if your postmortem process is uneven or emotionally charged, especially at first. NOT having a blameless postmortem is the single most common limiting factor we see in enterprises today. Without a healthy, generative approach to handling mistakes, any DevOps movement you initiate will end up being just words on a wall.
Remember the dysfunctions we’re trying to avoid: avoidance of accountability, and inattention to results. Showing our character under stress, and being open and honest about failures so we can get ahead of them for next time, is a game-changer. Try hosting a blameless postmortem the next time there’s a high severity outage at your company. You might be surprised at the positive returns you get by moving past blame and towards learning.
Make your postmortem process faster and clearer with the objective data-gathering made possible by Raygun. Drill into root causes faster, build precise timelines and understand exactly what underpins any incidents at code-level. Grab a free 14-day Raygun trial (right now if you like).


