'Monitoring is your lateral line', and more from the new book 'Achieving DevOps'
Posted Jun 28, 2019 | 6 min. (1210 words)The following article is an excerpt from the book Achieving DevOps, a novel about delivering the best Agile, DevOps and Microservices, written by Dave Harrison and Knox Lively. This article is published with the author’s permission.
A lateral line is how a fish monitors the surrounding water for changes in pressure, allowing it to understand the environment. This is how fish can survive in a very harsh, always-changing environment; without it, the fish is ‘blind’ and cannot survive. In a trout or a salmon’s sphere, sudden pressure change is the KPI that alerts them to potential danger or food.
For fish, weightlifters, and DevOps devotees, the statement holds true; if you can’t measure it, you can’t improve it.
Most people would not argue with this statement; yet coming up with the right numbers to track or even having a common measurement of what success looks like is a real struggle for many organizations. What are some keys to keeping the lateral line feeding the information you need to survive and thrive in a hostile and complex operating environment?
Information radiators come first
Let’s take the topic of pervasive information radiators as an example. Toyota made pervasive information displays a cornerstone of their Lean manufacturing process. Quality and the current build process state was constantly updated and available at a glance from any point on the factory floor.
When it comes to using displays to create a common awareness of flow, software appears to be lagging badly behind manufacturing. In most enterprises we’ve engaged with, monitors are either missing or only displaying part of the problem. Every team gathering area and war room should have at least one and preferably many displays.
Gathering metrics is too important to be optional or last in priority. We would never get in a car that didn’t have a speedometer and gas gauge front and center. Constant realtime monitoring and dashboarding is a critical part of safe operations for any vehicle. The same is true with the services and products we deploy; none are ‘fire and forget’ missiles. If it’s running in production, it must be monitored.
It’s not an overstatement to say instrumentation is one of the most valuable, impactful components of any application we build. Without it, we won’t know what aspects of the app are in use—meaning our backlog will be prioritized based on best guesses. And that ‘thin blue line’ of initial support will have no information on hand to triage and knock down common problems; second and third-tier responders will waste hours trying to reconstruct performance or operating issues because of blind spots in activity logs and a low signal-to-noise ratio.
And yet it’s often the first thing that’s thrown out when budgets are tight. As Jody Mulkey of Ticketmaster put it to us:
“We started a program where we put the emphasis on ‘breathing the customer’s oxygen’. We passed out gift cards and had our people attend events and take in what the total experience was like. I guarantee you, once a developer goes to a One Direction concert at Madison Square Garden and sees what happens when a scanner goes down—being almost trampled by 5,000 screaming girls will get them to see availability in a whole new light!
It’s a commandment with us, we do not ship features that are unmonitored. If it’s important enough to create software, then it’s important enough to monitor – period. “Monitoring is like testing, only it’s in production. Otherwise, how do we know we’re making progress? So when we encounter some relic of a system, the first thing we do is build a fence around it and capture its inputs and outputs with monitoring. That establishes our situational awareness. And we don’t let people go cheap on this or scrap it. Any decent feature we build is going to cost at least $100K. Are you telling me you’re not going to drop $5K to make sure it’s up and running?
“Things like monitoring and peer reviews are some of those little things that end up add up to a very big thing, a kind of religion. I don’t have to tell people to do it, just like I don’t tell people they have to wear pants when they come to work. That’s just the way we do business. We instrument EVERYTHING. And we make it simple – with a couple of annotations or keystrokes, your app is tied into our dashboard. And all data is by default open if it’s not PI. It helps us find more problems when more eyes are on the data.”
A clean dashboard showing valuable numbers is a first-class citizen of the project – the veins of your app’s circulatory system. Your code reviews and design reviews should drill in on how monitoring will be set up and what alert thresholds are appropriate.
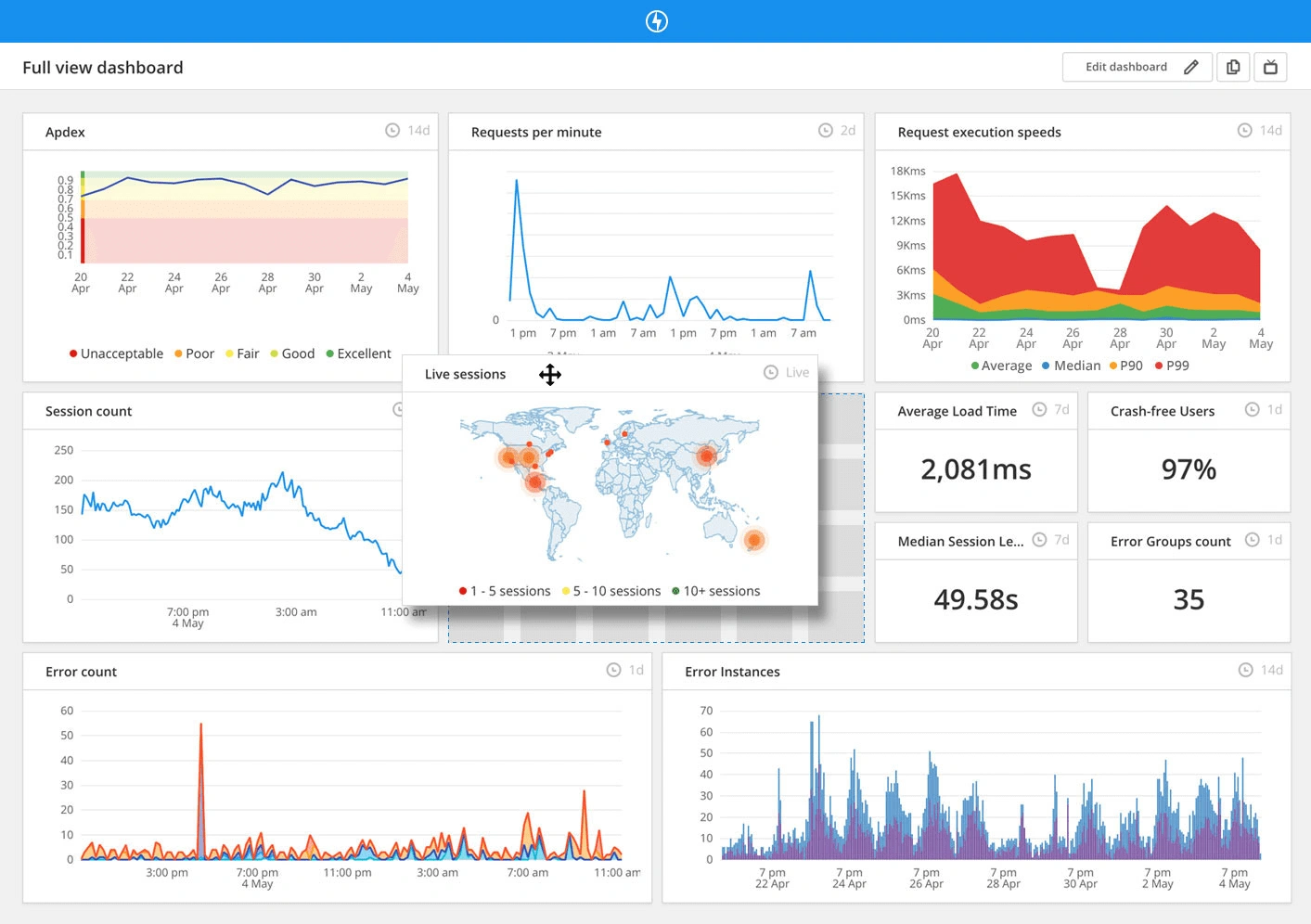 An example of Raygun’s monitoring dashboard
An example of Raygun’s monitoring dashboard
There’s no excuse not to start
One common fear we hear often is that it’s somehow difficult and time-consuming to get monitoring set up. Actually, setting up monitoring is almost frighteningly easy. (Setting up the right kind of monitoring is where the pain comes in. We’ll dive into that in the book!) As with all things, starting simple is the key: what about timing how long database queries take? Or how long some external vendor API takes to respond? Or how many logins happen throughout the day?
In my upcoming book “Achieving DevOps”, the team lead makes a critical mistake early in the book – he waits too long to get to monitoring. It honestly should have been first, and would have saved the team some time-wasting cul-de-sacs. The most formidable enemy in any transformation on the scale that DevOps demands is inertia. And the most powerful weapon you have to wield against falling back into old habits is the careful and consistent use of numbers to tell a story. Delaying or deferring monitoring cost the team months of wasted effort.
Once you start instrumenting your app, it becomes addictive. App metrics are so useful for a variety of things, you’ll wonder why you didn’t get started sooner. Your business partners, who usually were completely in the dark before, will welcome more detail around issues and changes shown in your information radiators. And it’s a key part of completing the feedback cycle between your development and Ops teams.
There’s a variety of great tools out there; it’s almost impossible to pick a bad one. Do what our friend JD Trask, CEO and Co-Founder of Raygun recommends – take a Friday afternoon, and just get it done.
Some customers have reduced errors by 99% by using performance monitoring tools like Raygun Crash Reporting, Real User Monitoring and APM.
Dave Harrison is an Application Development Manager at Microsoft where he utilizes his expertise and technical background to help solve dev team maturity bottlenecks and help clients deliver better software, faster to add more business value.
Knox Lively is Lead DevOps Engineer at Songtrust, a NYC-based music startup. As a seasoned DevOps engineer in the entertainment industry, he has built out entire DevOps departments, consulted as an architect with various firms, and tried his hardest to automate himself out of a job.


