What is MTTR? How to measure and improve your Mean Time to Recovery
Posted Jun 7, 2018 | 6 min. (1106 words)Complex distributed systems run just about every service imaginable. Healthcare systems that monitor patient health, security systems, and financial systems are all mission-critical. Downtime, or lack of availability, loses money and can even put lives at risk.
These systems must be monitored. Many measurements are useful to keep systems running with as little downtime as possible. One of those is Mean Time To Recovery. (MTTR.)
What is MTTR?
MTTR or Mean Time to Recovery, is a software term that measures the time period between a service being detected as “down” to a state of being “available” from a user’s perspective. This measurement can then be used to calculate the financial impact on the company.
The “R” in MTTR can refer to several things: Repair, Respond, Recover. We’re going to talk about Recovery, which we’ll define as bringing a service from a “down” state to an “available” state, from the perspective of users.
“Mean Time To” is a standard measurement of an average time duration between two events, often used in manufacturing. Mean Time to Recovery is the average time between the detection of outages and the recovery of the service.
Here’s an example: Suppose a system has 18 outages in a 90-day period. The time duration between detection of the outage and resolution is the Time to Recovery for each individual outage.
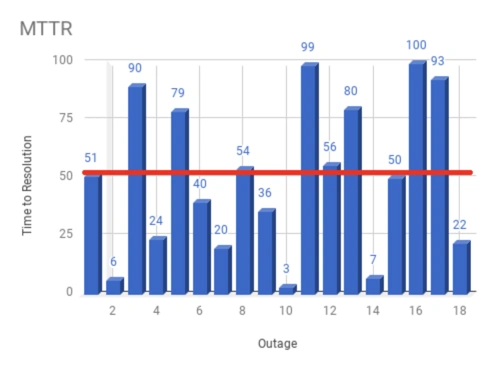
This chart displays 18 individual outages. Each outage has a time duration from the moment the outage is detected, to the moment the service is recovered. “Recovered,” in this context, refers to user experience. If users are able to use the system, the system is recovered. The mean, or average, time between detection and recovery is 51 minutes, so the MTTR for this 90 day period is 51 minutes.
Why is MTTR a useful measurement?
Mission-critical systems must be monitored to respond to degraded performance and total outages. Monitoring means measuring metrics such as response times, errors, and requests per second. These metrics provide information to teams that can be used to improve performance and reliability. MTTR is a metric that measures the availability of systems. Operations and Development teams use MTTR to support contracts such as Service Level Agreements (SLA).
Service Level Agreements (SLAs) are contracts between internal teams, or between a service provider and a client. SLAs can only be enforced if availability is measured. It’s also impossible to improve availability if it is not measured.
How is MTTR measured?
MTTR is a measurement of failure detection to the recovery of service, so the “clock” starts when failures are detected. This begs the question: how does your organization detect failure?
Many enterprises use IT Service Management tools to create tickets when a failure is reported. Tickets are generally created by a person. Ticket creation can also be automated by monitoring systems. However your organization does it, the first record of a problem “starts the clock” on an individual outage event.
Just as importantly, the clock “stops” when the issue is resolved. If a ticketing system is used to report the failure, the same system should be used to report resolution. If your enterprise is not deliberately measuring MTTR, you may not have a clear policy for reporting service recovery. The closing of tickets may be treated as an administrative step, with no urgency to report that the affected service(s) have been recovered. This may affect the accuracy of your MTTR reporting.
Your ITSM systems can be used to measure MTTR, but only if Operations staff are aware of the need. Most ticketing systems can be customized. You may prefer not to use ticket closure as the “clock-stopping” event for outage duration measurements. Look into adding a “time-resolved” field to your tickets.
Operations can use the ticket open time as the beginning of the outage, and the “time-resolved” value as the end time. Train the Operations teams to “stop the clock” on tickets as soon as service is restored. You can then accurately report on MTTR from your ITSM system.
How to improve MTTR
Measure it
The first step in improving MTTR is to measure it, as discussed above. You’ll need a large enough dataset, including outages over time, to develop an accurate picture of your MTTR. If possible, automate the creation of tickets using an Application Performance Management (APM) system. If you don’t use a ticketing system, log the outage as an alert. Operations teams should work each outage problem to resolution, then record a “clock-stopping” event to be used for reporting purposes.
An APM tool can help by measuring the extent and location of production related outages. Raygun, for example, detects and diagnoses problems in pre and post-production environments, so software teams don’t fall victim to performance issues affecting revenue.
Document outages
Your first clear MTTR measurement over time is a baseline. The best way to improve overall MTTR is one outage at a time. Each outage is an individual event. However, there may be common root causes. Perform a blameless postmortem for every outage. The purpose of the postmortem is to document the event, the details surrounding it, and the steps used to resolve it.
Documenting outages will help Development and Operations (DevOps) teams understand what led to a particular outage. This may, with some engineering, help prevent the same type of outage in the future. At the minimum, it will help train teams to recognize the outage faster next time, thus reducing Mean Time to Recovery. Repeat that process for each outage, and MTTR should be reduced over time.
Use modern operational practices
It’s important to ensure that your Operations teams have the bandwidth to address problems as they occur. When Ops teams are overworked, they cannot respond quickly to critical alerts.
Google has developed an Operational practice called Site Reliability Engineering. SRE is, perhaps, the most concrete example of DevOps practice in the IT industry. It offers a variety of best practices in the field of Operations. These practices are useful in measuring and improving MTTR. They include postmortems and strongly-defined terms for availability and reliability. If your enterprise maintains mission-critical systems, you can almost certainly derive some useful practices from SRE.
Summary
It’s not possible to improve that which is not measured. Mean Time To Recovery measures the availability of systems, which in turn allows an enterprise to make availability commitments.
Those commitments, Service Level Agreements, may be made between internal teams, or with external clients. Measuring MTTR is the first step to improving it. Operational practices such as postmortems will help reduce individual outage recovery times, thus leading to lower MTTR overall.