Investigating OAuth tokens
Posted Nov 5, 2014 | 3 min. (545 words)We have been working on a proper read API for Raygun for a little while now and have a few customers using this in a limited beta test. One of the things that we wanted to get right for this was proper authorisation and this meant that we needed an OAuth solution. As our main web technology is .Net we settled on the standard for this, which is the DotNetOpenAuth library. This library handles all of the token generation and signing, following the OAuth 2.0 standard. This worked really well and was relatively straight forward to plug into our site and have clients retrieving OAuth tokens for users.
While implementing this I found little documentation on how the tokens are structured, so I wanted to cover off what I discovered while consuming them with our NodeJS API.
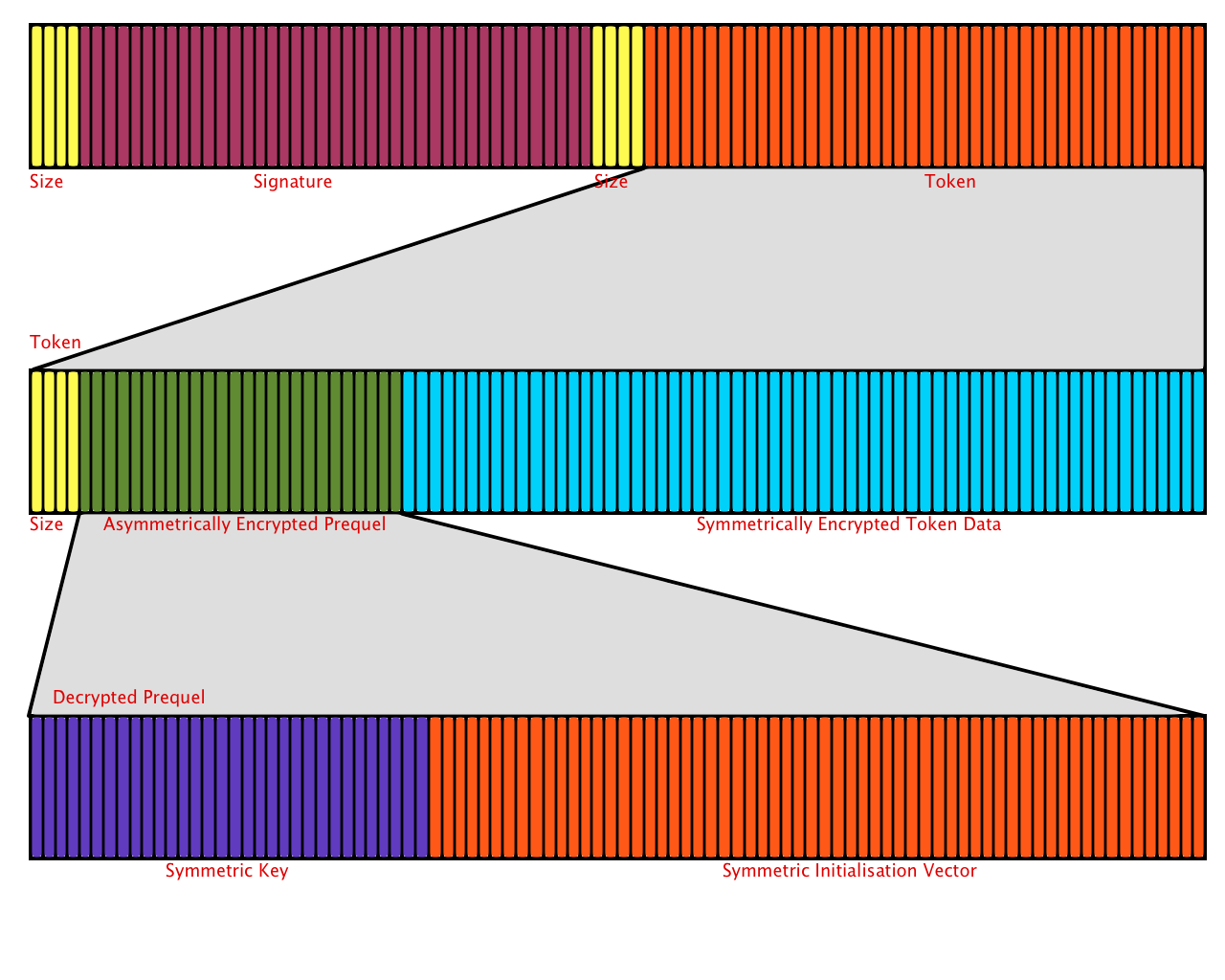
The token is transmitted as a web safe base64 string. This is a base64 string that has had ‘+’ replaced with ‘-‘, ‘/’ replaced with ‘_’ and any ‘=’ padding removed. Once this has been reversed and we have the original base64 string, we can begin to decode it. The data is split into two parts. The first is a signature which we can verify using the public key of the authorisation server. The second is the actual token. To find the sections, we begin by reading a little endian 32bit integer from the binary data. This gives us the length of the signature that we need to read next from the data. We cap this to a maximum size to prevent malicious tokens from attempting to make us read to much of the data. After reading the signature, we then read another little endian 32bit integer which gives us the length of the token, which we can then read. The image below shows this, in yellow we have the Int32LE values that tell us the size of the next part.
We can then use the public key of the authorisation server to verify the signature. If this is successful, we can start to decrypt the second part of the data. This is also split into two sections. The first is the “prequel” which contains the symmetric key and initialisation vector used to decrypt the second half. The “prequel” has been asymmetrically encrypted with the resource servers public key. We need to decrypt this with the resource server’s private key. Once this is done we grab the first 32 bytes, which is the symmetric key and the rest of this data is the initialisation vector.
Using the key and initialisation vector we just obtained, we can then decrypt the second half of this piece of data. Once decrypted we have access to the query string formatted data, encoded in the token. This includes a timestamp and a lifetime value that we can use to check that this token is still valid. It also includes a user identifier, client identifier and the scopes that the token allows.
With all this information we can be assured that the token has not been tampered with and allows the requester to access the resources that they have been granted.
Raygun provides industry leading error tracking software for all major web and mobile programming languages. Why not check out our free trial today.