2.5X faster and 88% cheaper error resolution with GPT-4o mini and Raygun
Posted Jul 22, 2024 | 4 min. (750 words)In May, OpenAI released GPT-4o, which refined the GPT-4 architecture with native multi-modal input support, faster speeds, and a lower price per token. GPT-4o mini was released this week, making it even more cost-effective and quicker. This model is considered better than GPT-3.5 Turbo, being faster and smarter—a win all around.
Let’s test it in a real-world application to see how useful it is for software developers.
Unparalleled speed
Our testing revealed that GPT-4o mini operates at an impressive speed, immediately standing out in its efficiency. We timed the response time using Raygun’s AI Error Resolution feature and compared it to the GPT-4 and GPT-3.5 Turbo models. The difference was like night and day, with the GPT-4o mini being nearly 2 to 2.5 times faster than the GPT-4 and GPT-4 Turbo. Even when compared to its bigger brother, GPT-4o, and its predecessor, GPT-3.5 Turbo, the GPT-4o mini was slightly faster. However, some reports suggest it should be much quicker, indicating potential bottlenecks somewhere.
Accuracy of predictions
While speed is crucial for user experience, prediction accuracy is equally important. Although each subsequent model has maintained high benchmarks, there have been slight perceptions of reduced “intelligence” - the model’s ability to effectively understand and respond to complex queries. However, these differences are not hugely significant.
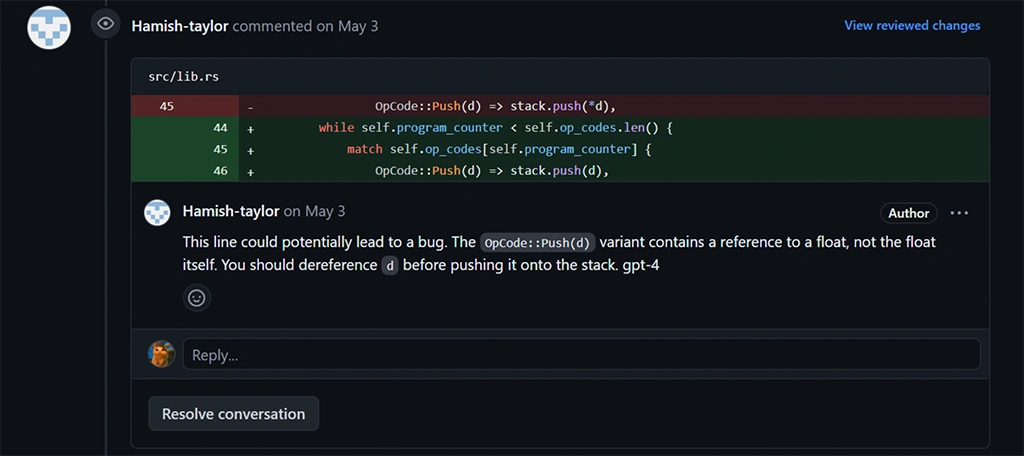
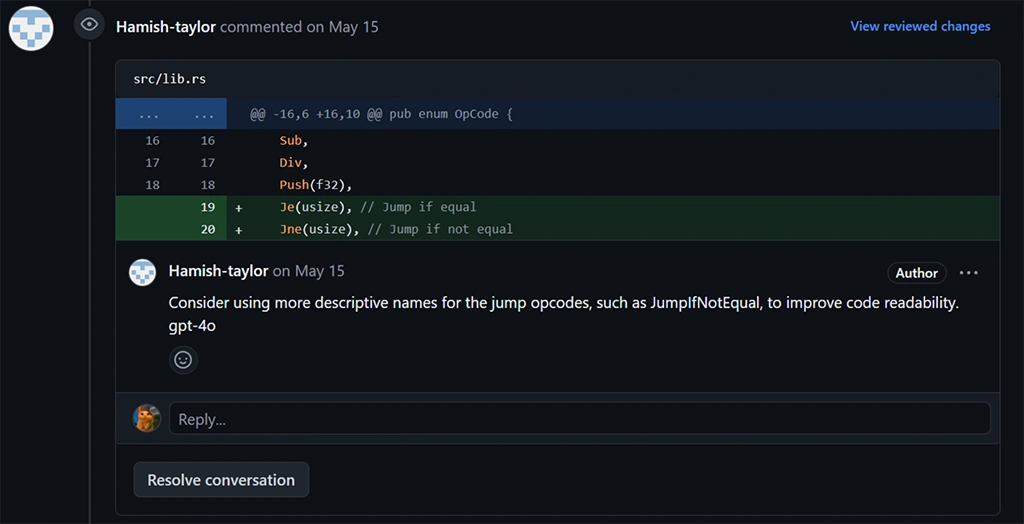
A favorite test of mine is to have the models perform a PR review where each model leaves its comments. This test identifies whether the model understands the context well. These results showed that GPT-4 still holds the top spot regarding accuracy and depth of understanding.
GPT-4 Comment - more interested in meaningful reviews
GPT-4o Comment - more interested in semantic reviews
Substantially cost efficient
While top-tier models like GPT-4 offer unmatched accuracy and depth, they come with high costs, which might only sometimes be practical for some use cases; this is especially true when handling large volumes of queries or working within budget constraints.
When cost is a significant consideration, GPT-4o mini is a game-changer, offering an impressive balance of performance and affordability. This cost efficiency can be a relief for many software developers and businesses. Here’s the breakdown of the costs for using GPT-4o mini:
-
Input tokens: $0.150 per 1 million tokens
-
Output tokens: $0.075 per 1 million tokens
In comparison, the costs for GPT-4 models are significantly higher*:
-
GPT-4 (8k context): $30.00 per 1 million input tokens and $60.00 per 1 million output tokens
-
GPT-4 (32k context): $60.00 per 1 million input tokens and $120.00 per 1 million output tokens
-
GPT-4 Turbo (128k context): $10.00 per 1 million input tokens and $30.00 per 1 million output tokens
-
GPT-4o: $5.00 per 1 million input tokens and $15.00 per 1 million output tokens
-
GPT-3.5 Turbo (0125): $0.50 per 1 million input tokens and $1.50 per 1 million output tokens
*Pricing is accurate as of July 22, 2024, based on information from the OpenAI Pricing and OpenAI Help Center.
Using OpenAI’s current pricing, we calculated the total expenses for processing 1 million input and 1 million output tokens for each model. We found that GPT-4o mini is approximately 88.75% cheaper than the next most affordable GPT version, GPT-3.5 Turbo, and 98.88% cheaper than GPT-4o.
The substantial difference in pricing makes GPT-4o mini a desirable option. It allows developers to leverage advanced AI capabilities without incurring high costs. It is particularly beneficial for startups and smaller teams or use cases such as chatbots, large-scale software error analysis, and other applications where speed and cost are critical.
While GPT-4o mini may not surpass GPT-4 in every aspect, it performs exceptionally well for most tasks. It’s an excellent choice for scenarios where rapid responses and cost efficiency are more critical than having the highest level of accuracy.
Raygun’s AI Error Resolution gets a power boost with GPT-4o mini
We’re excited to announce the integration of OpenAI’s GPT-4o mini model into Raygun’s AI Error Resolution feature. This upgrade boosts performance, providing our customers with top-tier tools for smooth and efficient operations. Try it today and experience the difference for yourself:
Already a Raygun customer?
You can enable the AI Error Resolution feature by clicking on any error group in Crash Reporting and then clicking on the “AI Error Resolution” button at the top right of the page. Then, select “OpenAI” from the AI provider dropdown, select “GPT-4o mini” from the model version dropdown, and enjoy the benefits of faster, cost-effective error resolution.
Not a Raygun customer yet? Try out Raygun Crash Reporting free for 14 days! No credit card is required.