.NET Core or Node.js? [We increased throughput by 2,000%]
Posted May 19, 2017 | 5 min. (1012 words)A few months ago, Raygun was featured on the Microsoft website with how we increased throughput by 2,000 percent with a change from Node.js to .NET Core.
The performance improvements were immediate and nothing short of phenomenal.
In fact, using the same size server, we were able to go from 1,000 requests per second per node with Node.js, to 20,000 requests per second with .NET Core. Check out the case study for a quick refresh.
This is a 2,000 percent increase in throughput, which means we reduced our server count by 60 percent.
These results are astounding, and understandably, there were a few questions around our infrastructure, and the exact scenario which enabled us to gain these results.
Raygun helps you to help benchmark, measure, and improve application performance.
How we got from Node.js to .NET Core
We originally built using Mono, which just bled memory and would need to be constantly recycled. So we looked around at the options and what would be well suited to the highly transactional nature of our API.
We settled on Node.js, feeling that the event loop model worked well given the lightweight workload of each message being processed. This served us well for several years.
As our test case is our production system, we are unable to release the code to help others to reproduce the results. However, we did also get asked about which EC2 instances we used and for any other technical information that would help understand where the gains have come from.
Adding context to the increased throughput
We’re really excited about the direction Microsoft is taking with .NET Core. Even with our impressive performance gains from moving to .NET Core 1, there’s more coming in .NET Core 2, with another 25 percent lift in performance.
Performance is absolutely a feature. So much so, that Raygun includes a Real User Monitoring capability to track software performance for customers.
We know the better performance we deliver, the happier we make our customers, and the more efficient we can run our infrastructure. 40% of users will stop using a site that takes longer than three seconds to be ready.
No offence to Jeff, but I’d far prefer to pour our dollars into improving our product than into our hosting bill.
In my role as CEO, I focus more on the question: “How can I deliver more value to our customers?”
So, making the platform more efficient with better systems means we can deliver more for the same price. Squeezing more out of our infrastructure investment means we can direct that spending into building features our customers need and love.

Which EC2 we used
In terms of EC2 we utilized c3.large nodes for both the Node.js deployment and then for the .NET Core deployment. Both sit as backends behind an nginx instance and are managed using scaling groups in EC2 sitting behind a standard AWS load balancer (ELB).
In terms of where the gains have come from, when we started to look at .NET Core in early 2016, it became quite obvious that being able to asynchronously hand off to our queuing service greatly improved throughput.
Unfortunately, at the time, Node.js didn’t provide an easy mechanism to do this, while .NET Core had great concurrency capabilities from day one. This meant that our servers spent less time blocking on the hand off, and could start processing the next inbound message. This was the core component of the performance improvement.
Beyond just the async handling, we constantly benchmark Node, and several of the common web frameworks. Our most recent performance test between Hapi, Express, and a few other frameworks found the following results (you can read about the environments and how to replicate the test here.)
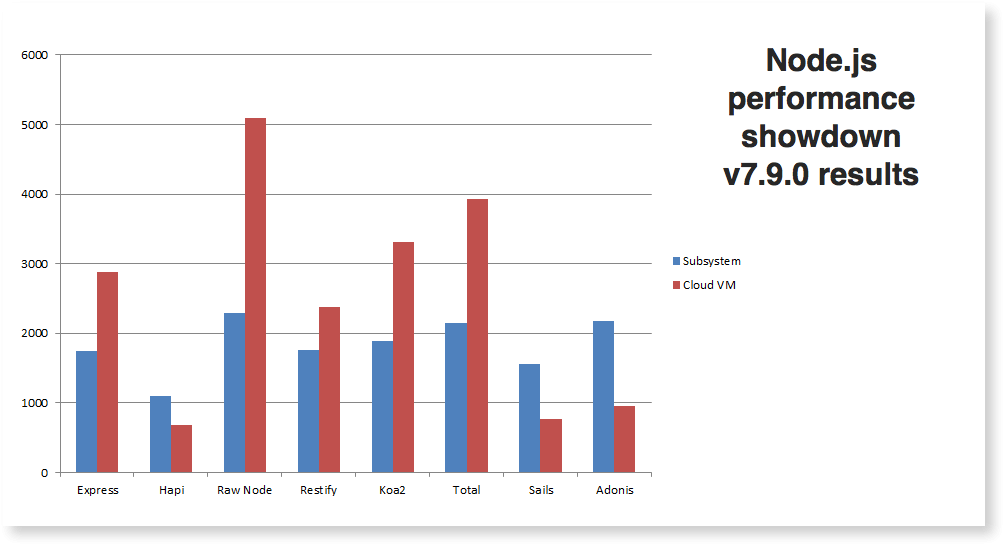
We were previously using Express to handle some aspects of the web workload, and from our own testing we could see that it introduces a layer of performance cost. We were comfortable with that at the time, however the work that Microsoft have invested in the web server capabilities has been a huge win.
Memory usage
Another popular question about our increased throughput was around memory usage, specifically if we achieved any gain, and if this was something we specifically needed to manage with high throughput. Indeed we did see a gain, although in both cases memory was fairly static.
However, our Node.js deployments would operate with a 1GB footprint, and the .NET Core deployment reduced the size of that footprint to 400MB. For both deployments we have a level of “working” memory involved associated with each concurrent active request. Similarly, with the improvements to the overall footprint, the operating overhead was reduced in moving to .NET Core.
It’s hard to overstate the efforts they’ve put in. (Seriously. Go and watch some of the GitHub discussions, you’ll see all sorts of incredible, crazy optimizations to deliver amazing performance.)
Raygun aren’t the only folks benefiting from the performance improvements of increased throughput.
MMO Age Of Ascent also benefited from a switch to .NET Core, with 2300 percent more request processed per second, a truly amazing result!

ASP.NET 4.6 and Node.js are bottom left. This graph shows rapid strides in performance the leaner, more agile and componentized stack has taken (blue Windows, orange Linux) in just a few short months.
Two schools of thought
From the questions we received around the specifics of our performance improvements, there seems to be two schools of thought:
- Of course it’s faster, Node is slow
- You must be doing Node wrong, it can be fast
In my view, this is an incredibly simplistic view of the world. Node is a productive environment, and has a huge ecosystem around it, but frankly it hasn’t been designed for performance.
Could we have got more out of it? Sure. Do I think we could get it to beat .NET Core for our specific use case?
No, probably not.
Further Reading
-
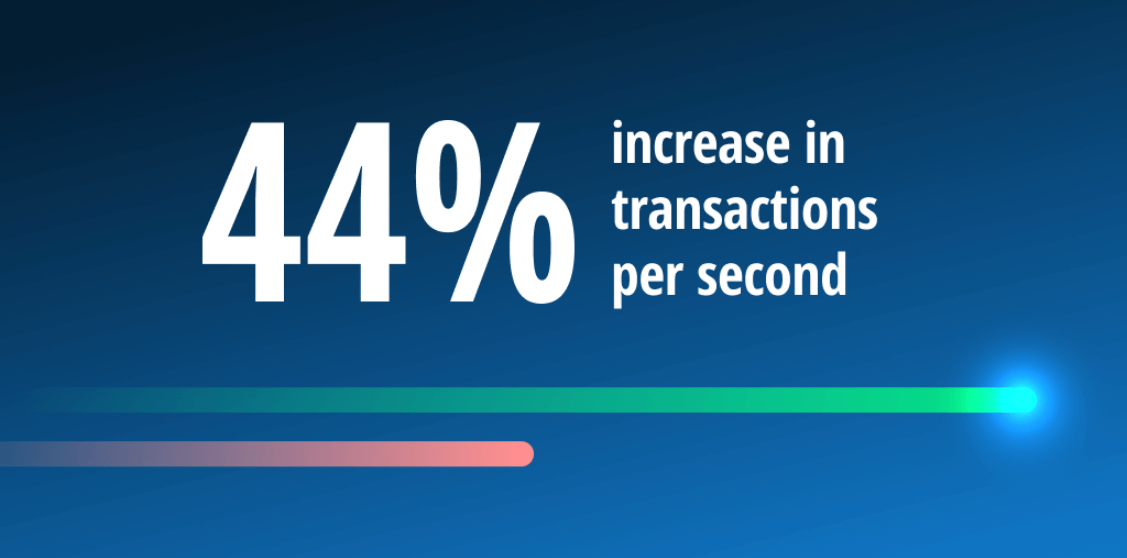
How Raygun increased transactions per second by 44% by removing Nginx
Here at Raygun, improving performance is baked into our culture. In a previous blog post, we showed …
-

Achieving a 12% performance lift migrating Raygun's API to .NET Core 3.1
Here at Raygun, improving performance is baked into our culture. We don’t just think about our …
-
How we scale Raygun's architecture to handle more data
Due to the huge importance of sourcemaps in the workflow of our customers, sourcemaps are a crucial …