Benchmarking OpenAI models for automated error resolution
Posted Aug 7, 2024 | 11 min. (2288 words)Large Language Models (LLMs) are increasingly shaping the future of software development, offering new possibilities in code generation, debugging, and error resolution. Recent advancements in these AI-driven tools have prompted a closer examination of their practical applications and potential impact on developer workflows.
This article explores the effectiveness of LLMs in software development, with a particular focus on error resolution. Drawing from industry-wide observations and insights gained through my work with AI Error Resolution at Raygun, I’ll analyze LLMs’ current capabilities and their implications for the future of development practices. The discussion will weigh both the promising advancements and the challenges that arise as these technologies integrate into our daily work.
OpenAI models for software development
OpenAI has successfully released newer, faster, and allegedly smarter models. While benchmark sites confirm these results, we see more and more anecdotal data claiming that these models feel dumber. Most existing benchmarks focus purely on the logical reasoning side of these models, such as completing SAT questions, rather than focusing on qualitative responses, especially in the software engineering domain. My goal here is to quantitatively and qualitatively evaluate these models using error resolution as a benchmark, given its common use in developers’ workflows.
Our comprehensive evaluation will cover several models, including GPT-3.5 Turbo, GPT-4, GPT-4 Turbo, GPT-4o, and GPT-4o mini. We’ll use real-life stack traces and associated information sent to Raygun to assess how these models handle error resolution. Factors such as response speed, quality of answers, and developer preferences will be thoroughly examined. This analysis will lead to suggestions for extracting the best responses from these models, such as the impact of providing more context, like source maps and source code, on their effectiveness.
Experimental methodology
As mentioned, we will evaluate the following models: GPT-3.5 Turbo, GPT-4, GPT-4 Turbo, GPT-4o, and GPT-4o Mini. The specific variants used are the default models provided by the OpenAI API as of July 30, 2024.
For our evaluation, we selected seven real-world errors from various programming languages, including Python, TypeScript, and .NET, each combined with different frameworks. We selected these by sampling existing errors within our Raygun accounts and personal projects for a representative sample. Errors that were transient or did not point to a direct cause were not selected.
| Name | Language | Solution | Difficulty |
|---|---|---|---|
| Android missing file | .NET Core | The .dll file that was attempted to be read was not present | Easy |
| Division by zero | Python | Division by zero error caused by empty array - no error checking | Easy |
| Invalid stop id | TypeScript | Stop ID extracted from Alexa request envelope was not valid - Alexa fuzz testing sent an invalid value of xyzxyz | Hard |
| IRaygunUserProvider not registered | .NET Core | IRaygunUserProvider was not registered in the DI container, causing a failure to create the MainPage in MAUI | Medium |
| JSON Serialization Error | .NET Core | Strongly typed object map did not match the JSON object provided, caused by non-compliant error payloads being sent by a Raygun client | Hard |
| Main page not registered ILogger | .NET Core | ILogger was added, but MainPage was not added as a singleton to the DI container, causing ILogger<MainPage> to error when creating MainPage | Medium |
| Postgres missing table | .NET Core/Postgres | Postgres missing table when being invoked by a C# program, causing a messy stack trace | Easy - Medium |
We then used a templated system prompt from Raygun’s AI Error Resolution, which incorporated information from the crash reports sent to Raygun. We tested this directly across all the models through OpenAI’s API. This process generated 35 LLM error-response pairs. These pairs were then randomly assigned to engineers at Raygun, who rated them on a scale of 1 to 5 based on accuracy, clarity, and usefulness. We had a sample of 11 engineers, including Software and Data Engineers, with mixed levels of experience, from engineers with a couple of years of experience to a couple of decades of experience.
In addition to the preference ratings, we will also conduct an analytical analysis of the models’ performance. This analysis will focus on two key aspects, response time and response length, which we will then use to derive multiple measures of these models’ effectiveness.
Developer preferences - qualitative results
General observations
We produced the graph below based on the engineers’ ratings. From this, there are a few distinct results that both support and contradict the anecdotal evidence. While this analysis focuses on error resolution, comparing these findings with other motivational factors discussed in the introduction is essential. For instance, the model’s effectiveness in error resolution might differ from their performance in tasks like code generation or debugging, which could influence overall perceptions. This broader perspective helps us understand the varying impacts of large language models on different aspects of a developer’s workflow.
Unexpected findings
We assumed GPT-4 would be the best model, but our software engineers rated it the worst. We can provide possible justifications for this result using the feedback from our software engineers and some of the analytic data, which we will show in the next section. These hypotheses resulted from my discussions with another engineer who closely followed this study. The later models of GPT-4 Turbo and onwards include code snippets when suggesting changes and engineers have reported that this gives them a better understanding of the solutions. GPT-4 did not generate snippets and has longer solutions than GPT-3.5 Turbo, indicating that engineers dislike longer responses that do not contain supplementary resources.
Error patterns
We also observed that the JSON validation error consistently received very low rankings across all model variants because the stack trace alone doesn’t provide a good solution for this error; this leads us to prompt engineering and what information is helpful when asking an LLM for help.
Contextual Influences
For .NET errors
.NET errors comprised all of these test cases except for the division by zero error and the invalid stop ID, as described in an earlier table. The result is that only the context the LLMs and engineers were made aware of was the stack trace, tags, breadcrumbs, and custom data. We see a higher reported score on these errors, likely because the engineers here at Raygun primarily work with .NET. However, in the cases where we tested different languages, we still observed good results.
Other languages
Based on the engineers’ comments, the reason for this is that in both the Python and TypeScript cases, the stack trace came with the surrounding code context. The surrounding code context was provided as part of the stack trace in Python, and in the TypeScript error, this was from the source maps with source code included. With this additional information, the LLMs could generate code snippets that directly addressed the errors, which also helped with the ratings of the later series of GPT-4 variants.
Performance insights
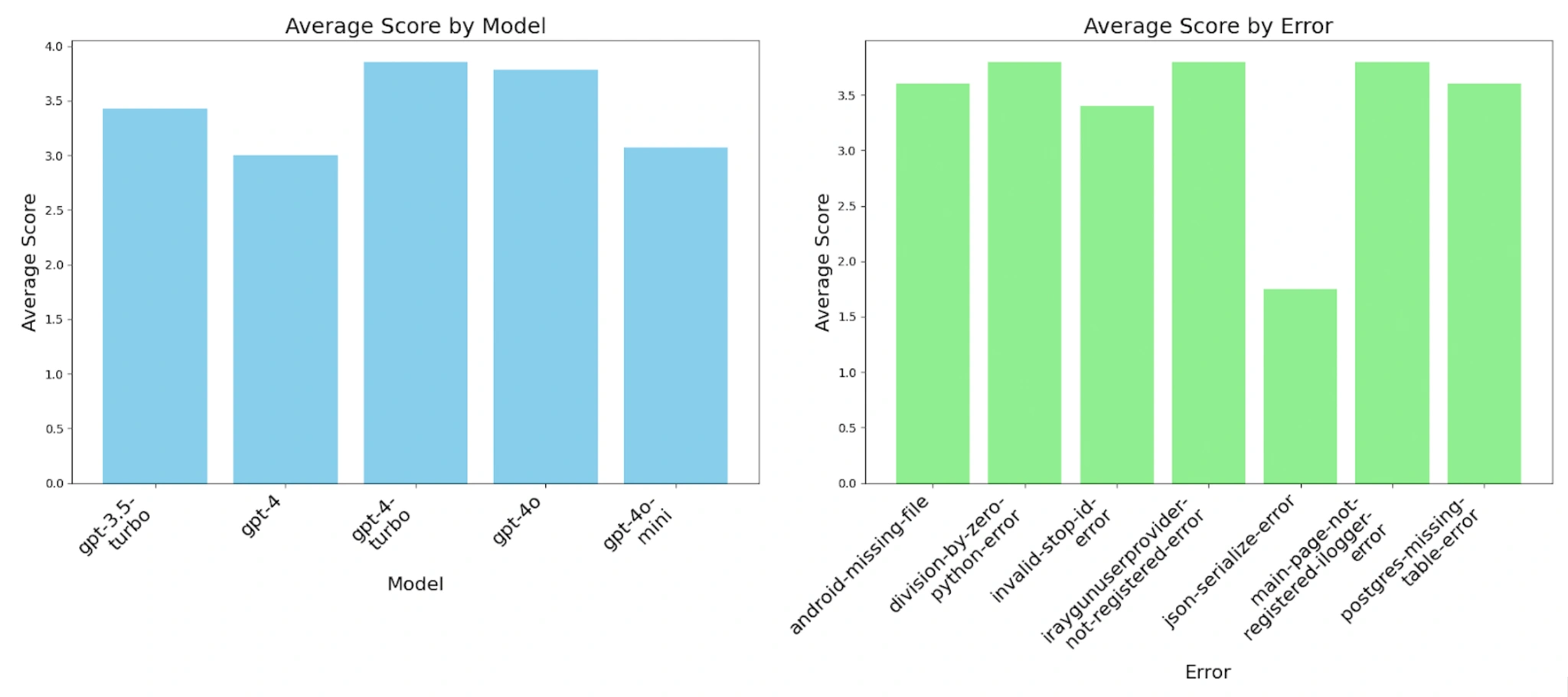
Decline in performance after GPT-4 Turbo
Looking at the scores of GPT-4 Turbo and onwards, we see a drop in ratings, especially once we reach GPT-4o, though these results are still better than GPT-4, and most are better than GPT-3.5 Turbo. If we remove the JSON serialization error as an outlier, we can still observe a decline in performance after GPT-4 Turbo. This result clearly shows that the performance of the GPT-4 series peaked with GPT-4 Turbo and declined afterward.
The importance of context for non-descriptive stack traces
This poor performance from the JSON serialization error is likely due to the need for supporting information on the underlying issue. Just looking at the stack trace makes it challenging to pinpoint the error, as there were multiple points of failure. Again, this plays into the topic of including more context, such as source code and variable values, to hint at where the issue could be. An enhancement here could be a RAG lookup implementation on the source code, so it is possible to associate the stack trace with the corresponding code.
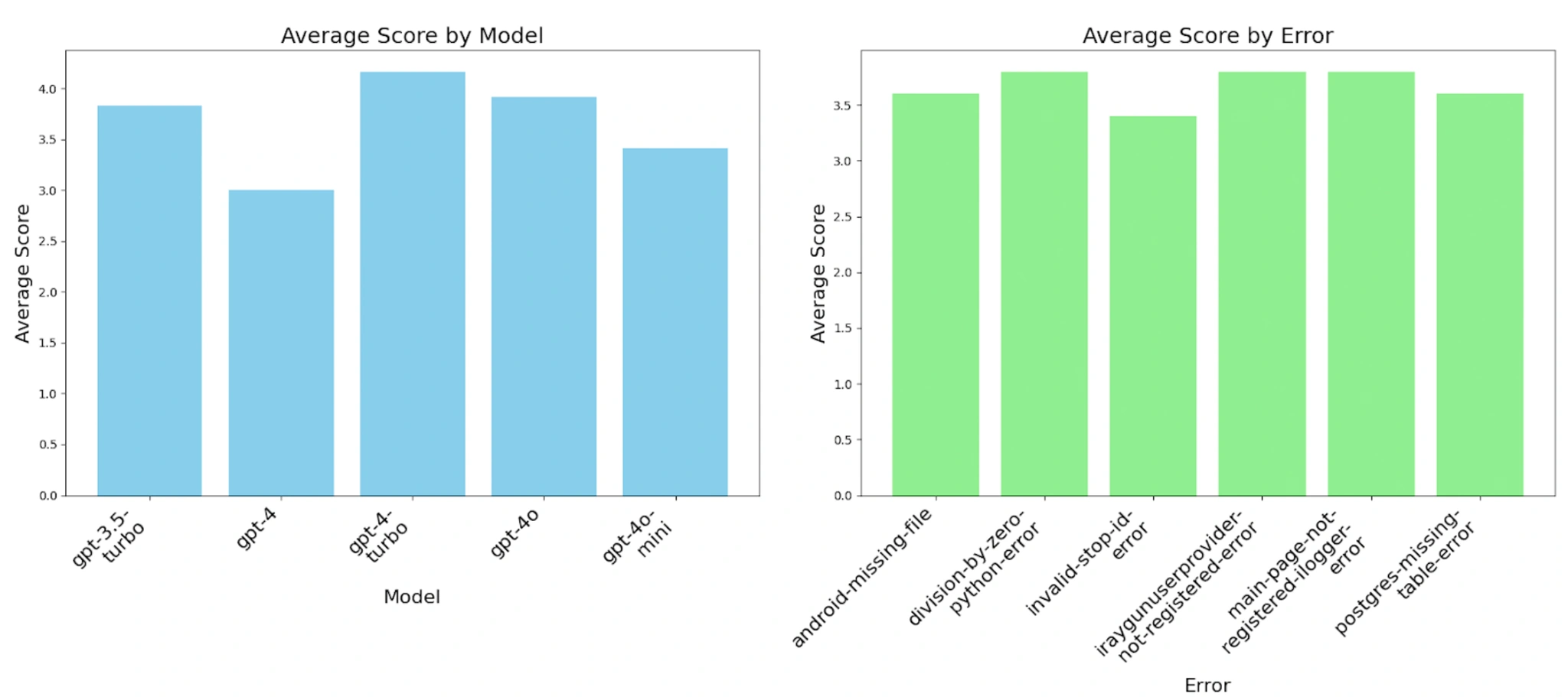
Impact of response length on performance
One theory for this worsening performance in the later models is the increase in response length. These models may fare better in heavier logic-based questions, but these longer responses are undesirable in everyday conversation. I have encountered this when asking questions about Python libraries, where I would like a direct answer. Each time, it would repeat a whole introduction section on setting up the library and useless information regarding my question.
If this is the case, we would like to see some corrections to this when newer models come out, such as GPT-5 and other competitors, but for now, the wordiness of these models is here to stay.
Analytical analysis - quantitative results
Response time and content generation
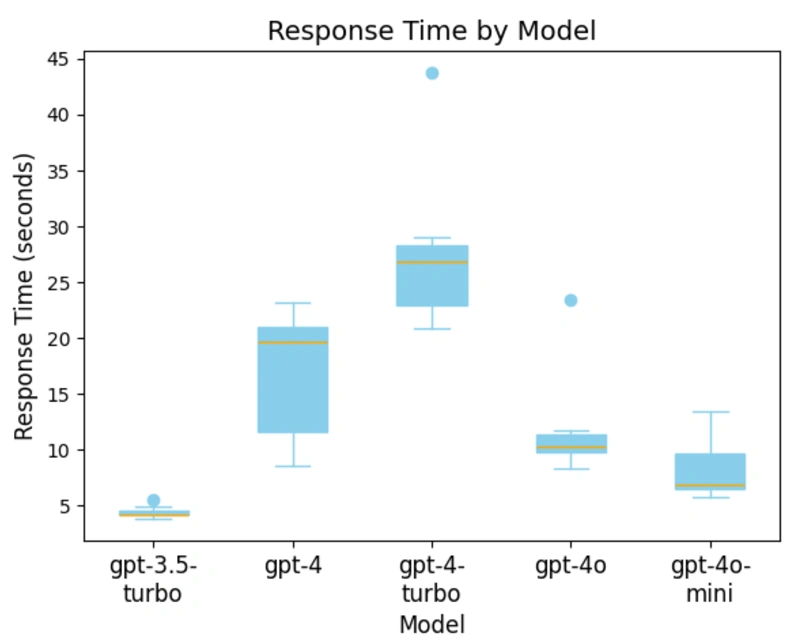
While qualitative evaluation of LLM responses is essential, response time/generation speed and the amount of content generated also significantly impact these tools’ usefulness. Below is a graph showing the average response time to create a chat completion for the error-response pair.
Interestingly, GPT-4 Turbo is the slowest model regarding average response time to generate a chat completion. This is a surprising result, as general understanding suggests that GPT-4 Turbo should be faster than GPT-4.
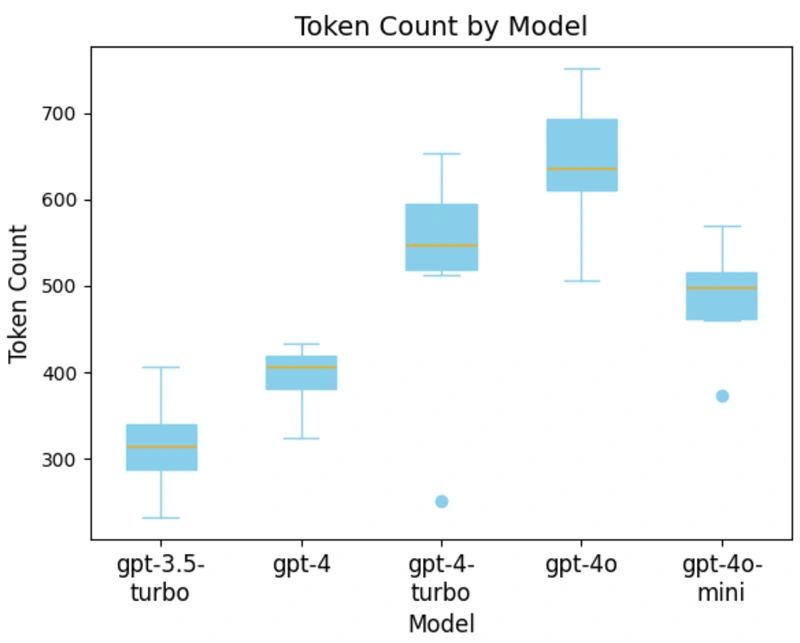
Token generation and model performance
The next graph explains this surprising result by measuring the average number of tokens generated by each model. This shows that GPT-4 Turbo generates significantly more tokens on average than GPT-4. Interestingly, the previous graph shows GPT-4o generates the most tokens but is still considerably faster than GPT-4 Turbo.
We also see that this trend of more tokens does not continue with OpenAI’s latest model, GPT-4o mini. The average number of tokens decreases compared to GPT-4 Turbo but remains well above GPT-4. The model generating the least number of tokens is GPT-3.5 Turbo, which aligns with the qualitative analysis results, where engineers preferred shorter responses as opposed to lengthier responses with no supplemental explanation.
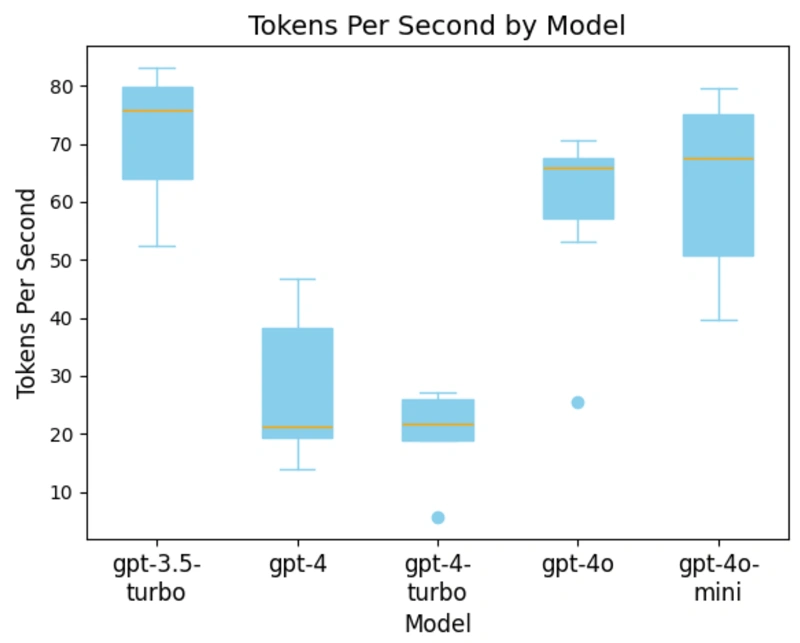
Per-token response time
After examining the response time and average token count by model, we can determine each model’s speed with respect to response time and token generation.
Below is a graph showing the per-token response time by model. Here, we see that GPT-4 is faster than GPT-4 Turbo, but this is due to an outlier in the data. Given its tendency to generate longer outputs, its overall response time is still longer than GPT-4. This may mean that GPT-4 Turbo is a less desirable model when it generates too much content.
 Note: GPT-3.5, GPT 4, and GPT-4o models use different tokenizers
Note: GPT-3.5, GPT 4, and GPT-4o models use different tokenizers
Comparison of GPT-4o and GPT-4o mini
Interestingly, the data shows that GPT-4o and GPT-4o mini have similar response speeds, contrasting with other sources’ findings. This discrepancy suggests that a larger sample size may be needed to reveal a more pronounced difference in their performance. Another explanation is that given that we are measuring the tokens per second by the total response time, we are slightly skewing the values to be lower due to Time To First Token (TTFT) and other network-related bottlenecks.
Scaling patterns
Plotting the response time versus token count, grouped by model, reveals distinct patterns in these models’ scaling. For GPT-3.5, GPT-4o, and GPT-4o Mini, the scaling is mostly linear, with an increase in token count leading to a corresponding increase in response time.
However, this pattern does not hold for the larger and older models of the GPT-4 series, where these two variables have no consistent relationship. This inconsistency could be due to a smaller sample size or fewer resources dedicated to these requests, resulting in varying response times. The latter explanation is more likely given the linear relationship observed in the other models.
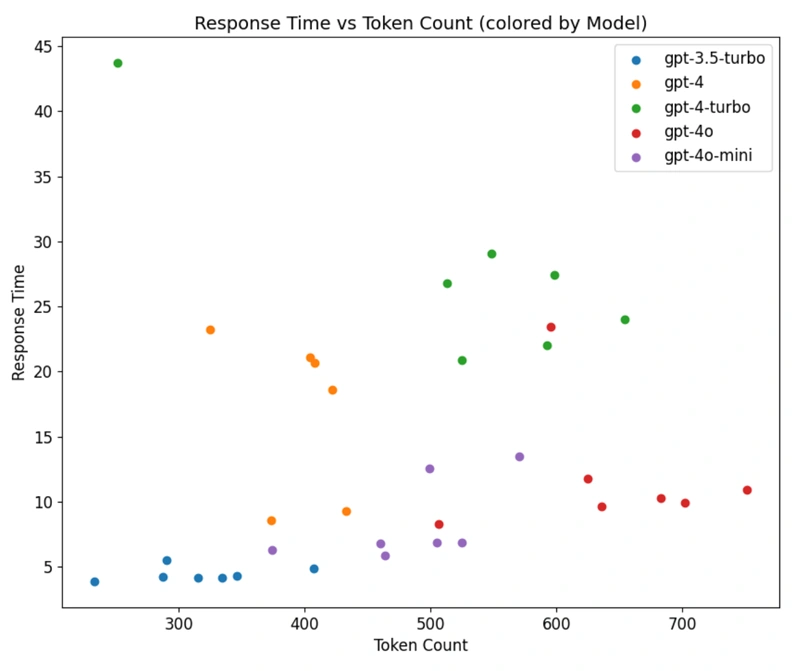
GPT-4 context limitations
One final piece of analysis emerged from generating these error-response pairs. While the GPT-4 model is competent, its context length is significantly limited for tasks requiring long inputs, such as stack traces. Due to this, one error-response pair could not be generated because the combined input and output would exceed the model’s 8192-token context window.
Joint analysis
After assessing the qualitative data, it is evident that GPT-4 Turbo is the best model for this task. However, comparing this to the quantitative data introduces response time and cost considerations. The new GPT-4o models are substantially faster and considerably cheaper than all other models, presenting a tradeoff. GPT-4 Turbo is the preferred choice if slightly better performance is required. However, if cost and speed are priorities, GPT-4o and GPT-4o mini are better alternatives.
Conclusion
In conclusion, our study provides mixed evidence regarding the performance of later models. While some newer models, like GPT-4 Turbo and GPT-4o, showed improvements due to their ability to include concise code snippets, others, like GPT-4, fell short due to verbose and less practical responses.
Key takeaways:
- Code snippets matter: Models that provide code snippets and explanations are more effective and preferred by developers.
- Context is critical: Adding surrounding code or source maps significantly enhances the quality of responses.
- Balance response length: Shorter, more concise responses are generally more helpful than longer, verbose ones.
- Regular evaluation: Continuously assess model performance to ensure you use the most effective tool for your needs.
- Mind context limits: Be aware of the context length limitations and plan accordingly.
By focusing on these factors, developers can better leverage LLMs for error resolution, ultimately enhancing their productivity and the accuracy of their solutions.
Future experiments that would complement this study could include a deeper analysis of code generation, as mentioned in the introduction. One possible experiment could involve taking the suggestions from the error resolution and providing additional context to the LLMs. Ideally, if this study were to be redone, it would be beneficial to include a wider variety of errors, including more challenging ones, and gather ratings from a more diverse set of engineers.
There’s never been a more exciting time to get started with Raygun! Try out Crash Reporting and all its features, including AI Error Resolution, free for 14 days.